5 SQL et RSQLite
5.1 Le langage SQL
Le SQL est un langage informatique créé spécifiquement pour manipuler des bases de données relationnelles. C’est le langage utilisé pour transmettre nos instructions au SGBD. Il permet de :
- Créer une base de données (
CREATE DATABASE). - Créer des tables et établir des relations (
CREATE TABLE). - Insérer des données (
INSERT). - Interroger les données par requête (
SELECT). - Supprimer des données ou des tables (
DROP,DELETE). - Mettre à jour des données ou des tables (
UPDATE,ALTER). - Supprimer la base de données (
DROP DATABASE).
Chacune de ces commandes est une instruction SQL envoyée au serveur pour manipuler et interroger la base de données.
Les instructions SQL sont près de la structure des phrases ordinaire en anglais. Vous trouverez le langage plus intuitif que beaucoup d’autres, avec notamment des instructions comme CREATE, JOIN, GROUP BY, etc. Le langage est déclaratif, il permet de décrire le résultat escompté, sans avoir à décrire comment l’obtenir. C’est une caractéristique voulue lors de sa création pour faciliter l’apprentissage et la lecture.
Le langage de programmation SQL et son utilisation sont détaillés dans la Section 5.3.
5.2 RSQLite pour interagir avec la base de données
Précédemment, nous avons vu les aspects importants de la conceptualisation d’une base de données avec les entités, les relations, les attributs et les types. Voyons maintenant comment passer au modèle informatique.
Conceptualiser et concevoir
- Le modèle conceptuel
- Faire une liste des variables
- Regrouper les variables dans des tables
- Établir le type d’association entre les tables
- Établir les clés primaires et étrangères
- Assigner les types de données aux variables
- Le modèle informatique
- Créer et se connecter au fichier de base de données
- Créer les tables et spécifier les clés
- Ajouter de l’information dans les tables
- Faire des requêtes pour extraire l’information
1. Connexion au serveur
Pour faciliter l’interaction avec la base de données et simplifier les manipulations, nous utiliserons RStudio et la librairie open source RSQLite qui contient le client SQLite3. RSQLite propose une interface dans R qui permet d’interagir avec les bases de données.
D’abord, il faut se connecter à la base de données à l’aide de la commande dbConnect() et sauver cette connexion dans un objet. Nous réutiliserons cet objet pour spécifier la connexion client-serveur à toutes les fois que nous enverrons une commande à la base de données.
# install.packages('RSQLite')
library(DBI)
ma_bd <- dbConnect(RSQLite::SQLite(), dbname="./my_database.db")
## !ATTENTION!: Ceci est mon chemin d'accès vers le fichier!
## Astuces: getwd() et setwd()
dbDisconnect(ma_bd)Ici, ma_bd est un objet contenant la connexion avec le serveur/fichier de base de données.
2. Créer les tables
creer_automobiles <-
"CREATE TABLE automobiles (
id INTEGER PRIMARY KEY AUTOINCREMENT,
marque VARCHAR(50),
modele VARCHAR(50),
annee INTEGER CHECK(annee >= 0),
consommation REAL CHECK(consommation >= 0),
cylindree INTEGER CHECK(cylindree >= 0),
);"
dbSendQuery(ma_bd, creer_automobiles)
creer_proprios <-
"CREATE TABLE proprios (
automobile_id INTEGER NOT NULL,
prenom VARCHAR(100) NOT NULL,
nom VARCHAR(100) NOT NULL,
no_permis VARCHAR(10),
PRIMARY KEY (prenom, nom),
FOREIGN KEY (automobile_id) REFERENCES mtcars(id)
);"
dbSendQuery(ma_bd, creer_proprios)Notez que les instructions SQL sont des chaînes de caractères. Elles sont envoyées au serveur avec la commande
dbSendQuery().
Types de données
Un type de données (VARCHAR, INTEGER, etc.) doit être spécifié pour chaque champ. Les types de données disponibles dépendent du SGBD utilisé. Pour SQLite, les types de données sont les suivants :
| Appelation | Type | Valeurs |
|---|---|---|
BOLEAN |
Boléen | vrai/faux |
INTEGER |
Entiers | -998, 123 |
DOUBLE, FLOAT, REAL |
Nombres réels | 9.98, -4.34 |
CHAR,VARCHAR, TEXT |
Chaine de caractères | lapin |
TIMESTAMP,DATE,TIME |
Dates et heures | 1998-02-16 |
VARCHAR est un type de données pour les chaînes de caractères de longueur variable. Il faut spécifier la longueur maximale de la chaîne de caractères entre parenthèses. Par exemple. le champs marque de la table automobiles est de type VARCHAR(50), c’est-à-dire qu’il peut contenir des chaînes de caractères de 50 caractères au maximum.
Clef primaire
La clé primaire est un champ ou un ensemble de champs qui identifie de manière unique chaque enregistrement d’une table. Elle est utilisée pour garantir l’unicité des enregistrements. La clé primaire est un index unique pour chaque enregistrement de la table. Elle est obligatoire pour chaque table.
Dans l’exemple ci-dessus, c’est le champ id qui est la clé primaire de la table automobiles puisque tous les champs de la table contribuent à l’unicité de la ligne. La combinaison des champs prenom et nom est la clé primaire de la table proprios.
id INTEGER PRIMARY KEY AUTOINCREMENT, spécifie que le champ id est la clé primaire de la table automobiles. Cette clé est de type INTEGER et est incrémentée automatiquement à chaque nouvel enregistrement. Aucune valeur n’est à spécifier pour ce champ lors de l’insertion d’un nouvel enregistrement, la base de données s’en charge automatiquement lors de l’injection d’une nouvelle ligne.
Clef étrangère
La clé étrangère est un champ ou un ensemble de champs qui référence une clé primaire d’une autre table. Elle est utilisée pour garantir l’intégrité référentielle des données Elle n’est pas obligatoire pour chaque table, par exemple, la table automobiles n’a pas de clé étrangère. Par contre, la table proprios a une clé étrangère automobile_id qui référence la clé primaire id de la table automobiles.
Contraintes
Les contraintes sont des règles qui sont appliquées aux données de la table. Par exemple, NOT NULL spécifie que le champ ne peut pas contenir de valeurs nulles. CHECK spécifie une condition qui doit être vraie pour chaque enregistrement.
3. Injecter des données
Une table de données peut facilement être copiée dans une base de données SQLite avec dbWriteTable().
automobiles_db <- dbConnect(RSQLite::SQLite(), dbname="./automobiles.db")
# Injection des enregistrements dans la B
dbWriteTable(con, append = TRUE, name = "automobiles", value = mtcars, row.names = FALSE)
dbWriteTable(con, append = TRUE, name = "proprios", value = iris, row.names = FALSE)
# Lister les tables
dbListTables(automobiles_db)
#> [1] "automobiles" "proprios"Pour ce faire, Les données doivent avoir le même format que la table dans laquelle elles sont insérées - Les colonnes doivent être dans le même ordre - Les noms des colonnes doivent être identiques - Les types de données doivent être compatibles -
4. Effectuer des requêtes
Pour envoyer des instructions, c’est la commande dbGetQuery() qui est utilisée. Son premier argument est l’objet contenant la connexion et le second les instructions SQL.
resr <- dbGetQuery(automobiles_db, 'SELECT * FROM automobiles LIMIT 4')
res
#> id marque modele annee consommation cylindree
#> 1 Ford F150 2016 21.0 6
#> 2 Honda Pilot 2013 21.0 6
#> 3 Honda Civic 2007 28.8 4
#> 4 Mazda MX5 2019 19.4 4Il est à noter que le code SQL est enchâssé entre
"pour former une chaine de caractères. L’omission des"est une cause d’erreur fréquente !!!
5. Fermer la connexion
Souvent oublié, il faut toujours fermer la connexion, se déconnecter de la base de données, avec la commande dbDisconnect() :
dbDisconnect(automobiles_db)5.3 Utilisation avancée du SQL
Les requêtes serviront à créer les tables de la base de données, à spécifier les clés, à filtrer les données et à extraire les données de la base de données. Pour ce faire, une certaine maitrise du langage SQL est nécessaire.
La requête type se découpe en quelques pièces détaillées dans les sections qui suivent :
SELECT champs
FROM table1
JOIN table2 ON table1.foreignKey = table2.primaryKey
WHERE critères
ORDER BY colonne1 ASC
LIMIT 10;Sélectionner des données
Les requêtes SQL sont une suite d’opérations séquentielles débutant par la définition des champs à être retournés SELECT, suivi de la table d’où les données sont extraites FROM et finalement des autres commandes :
SELECT champ1, champ2
FROM table1;Notez que toutes requêtes SQL se terminent par
;, sans quoi un message d’erreur est retourné.
* retourne tous les champs :
SELECT *
FROM table1;-- le double tiret permet d’écrire des commentaires :
-- Sélection de tous les champs
SELECT *
FROM table1;AS permet de renommer un champ dans la table retournée. La table table1 d’où les données proviennent n’est pas affectée par la commande. Cette astuce facilite l’organisation lorsque plusieurs champs ont le même nom ou que plusieurs champs sont agrégés en une seule colonne :
SELECT prenom_nom AS auteur, institution_id AS employeur
FROM table1;Filtrer la requête
WHERE spécifie les critères de la requête.
On ne peut pas filtrer (WHERE) avant que les opérations SELECT, FROM et JOIN soient complétées.
SELECT id, nom, no_telephonne, courriel
FROM client
WHERE ville = 'Sherbrooke';Champs numériques
Les opérateurs de comparaison standard tels que >=, <=, = sont accessibles pour les valeurs numériques.
Champs de texte
Les valeurs de texte sont filtrées avec LIKE et NOT LIKE :
SELECT id, nom, no_telephonne, courriel
FROM client
WHERE nom LIKE '%Beauchamp%';% tient pour n’importe quel caractère (Lyne Beauchamp, Julien Beauchamp-Lavallée) alors que _ est utilisé pour un seul caractère (WHERE nom LIKE 'Beauchamp_' : Beauchamp, Beauchamps, etc.).
Valeurs nulles
IS NULL et IS NOT NULL filtrent les valeurs nulles :
SELECT id, nom, no_telephonne, courriel
FROM client
WHERE nom IS NOT NULL;Filtres multicritères
On peut aussi effectuer des filtres multicritères avec AND et OR :
SELECT id, nom, no_telephonne, date_de_naissance AS annee
FROM client
WHERE
(annee <= 2008 AND annee > 2000)
OR (annee >= 1992 AND annee <= 1994);Filtrer par étapes
Une requête peut être divisée en plusieurs étapes pour faciliter la lecture et la compréhension. Chaque étape consiste en une table temporaire nommée. Par exemple, la requête suivante est divisée en trois étapes table1, table2 et un SELECT final :
WITH table1 AS (
SELECT id, nom, no_telephonne, date_de_naissance AS annee
FROM client
WHERE annee <= 2008 AND annee > 2000
),
table2 AS (
SELECT id, product_id, quantity
FROM commandes
WHERE quantity > 10
)
SELECT *
FROM table1
JOIN table2 ON table1.id = table2.id;Autres commandes
DISTINCT retourne les valeurs distinctes d’un champ :
SELECT DISTINCT nom
FROM client
WHERE nom IS NOT NULL;LIMIT limite le nombre de lignes retournées. Cette commande est particulièrement utile pour explorer la base de données :
SELECT id, nom, no_telephonne, courriel
FROM client
LIMIT 5;ORDER BY permet d’ordonner les rangées retournées en fonction d’une colonne. ASC est utilisé pour ordonner en ordre croissant, DESC pour ordonner en ordre décroissant :
SELECT id, nom, date_de_naissance
FROM client
ORDER BY date_de_naissance ASC;Agréger l’information
On parle d’agrégation d’information lorsque plusieurs valeurs sont utilisées dans le calcul d’une nouvelle composite. Les opérations les plus courantes sont la somme de plusieurs valeurs (SUM), l’extraction de la valeur maximale (MAX) ou minimale (MIN), la moyenne (AVG) ou le nombre d’éléments (COUNT) :
SELECT COUNT(*)
FROM clientDes opérations peuvent également être effectuées sur plusieurs champs telles que des sommes, des divisions, etc. Les opérateurs couramment utilisés sont : *, /, -, +.
GROUP BY définit les champs sur lesquels se fera l’agrégation des données. L’agrégation se fait dans la sélection des champs :
SELECT COUNT(id)
FROM client
GROUP BY magasin_idCette requête retourne le nombre de clients par magasin.
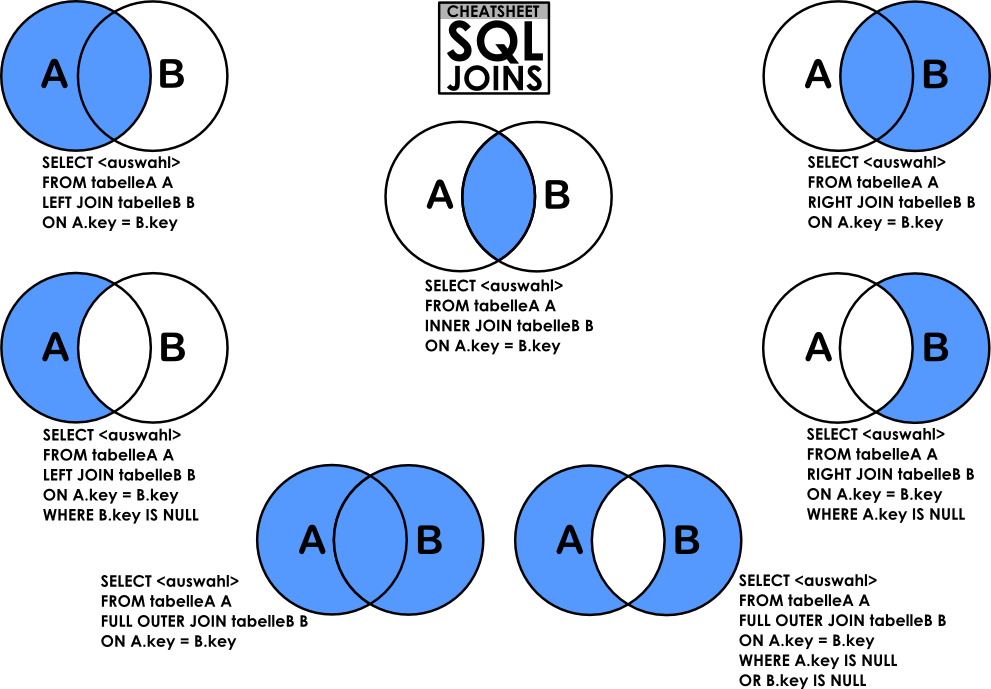
Jointures entre tables
Parfois, l’information requise est répartie dans plusieurs tables de la base de données. Dans ce cas, il faut joindre des données de plusieurs tables en utilisant les relations dans une requête.
Le type de jointure utilisé dépend du résultat attendu. Chaque jointure effectuée ne peut viser que deux tables : une table principale (nommée dans le FROM) et une table secondaire de laquelle des données sont extraites pour être ajoutées à la table principale. Chacun des types de jointures conserve les lignes et les informations de chacune des tables différemment.
Une jointure se fait en spécifiant les champs correspondants (clés étrangères), comme ici où les deux tables partagent un identifiant unique du magasin (id et magasin_id).
Imaginez deux tables :
client
| id | nom | courriel | magasin_id |
|---|---|---|---|
| 1 | Beaulieu | abc@gmail.com | 1 |
| 2 | Woot | Woot@hotmail.com | 1 |
| 3 | McNicols | mc@livre.ca | 4 |
| 4 | Tremblay | tremc3001@usherbrooke.ca | 8 |
| 5 | Beauregard | fun_1998@yahoo.com | 4 |
magasin
| id | no_civique | rue | code_postal |
|---|---|---|---|
| 1 | 1200 | King | J1K2S8 |
| 2 | 134 | Sherbrooke | B4L3V6 |
| 3 | 13333 | St-Denis | F2H5F5 |
| 4 | 123 | Main | L4X1A7 |
| 5 | 98422 | 3è rang | L1L4D6 |
Voici quelques exemples de situations que vous pouvez rencontrer :
Lateral join
Le lateral join est un type de jointure entre tables très pratique de par sa simplicité. Cependant, il peut produire des résultats contre-intuitifs puisque toutes les lignes correspondantes des tables seront retournées. Par exemple, la jointure latérale des tables magasins (5 lignes) et client (5 lignes) par le champ id du magasin produira un jeu de données de 7 lignes puisque le magasin 1 et 4 ont chacun 2 clients. Ces lignes seront donc dupliquées :
SELECT client.id, nom, magasin.id, code_postal
FROM magasin, client
WHERE client.magasin_id = magasin.id;| id | nom | magasin_id | code_postal |
|---|---|---|---|
| 1 | Beaulieu | 1 | J1K2S8 |
| 2 | Woot | 1 | J1K2S8 |
| 3 | McNicols | 4 | L4X1A7 |
| 4 | Tremblay | 8 | NULL |
| 5 | Beauregard | 4 | L4X1A7 |
Notez que le champ d’une table est spécifié avec le format
table.champ. Cela permet d’être explicite sur le champ visé puisqu’il peut y avoir de la redondance entre les tables, comme ici avec les colonnesid.
Left join
Le LEFT JOIN est la jointure la plus populaire puisqu’elle conserve les lignes de la table principale (de gauche) et ne joint que les colonnes de la seconde table (de droite) aux lignes correspondantes. Notez que lorsqu’il n’y a pas de correspondance, une valeur NULL est retournée :
SELECT client.id, nom, magasin.id, code_postal
FROM client
LEFT JOIN magasin ON client.magasin_id = magasin.id| id | nom | magasin_id | code_postal |
|---|---|---|---|
| 1 | Beaulieu | 1 | J1K2S8 |
| 2 | Woot | 1 | J1K2S8 |
| 3 | McNicols | 4 | L4X1A7 |
| 4 | Tremblay | 8 | NULL |
| 5 | Beauregard | 4 | L4X1A7 |
Inner join
Le INNER JOIN ne renvoie qu’une rangée des tables ayant un champ contenant une valeur commune. La requête suivante ne retourne que 4 lignes puisque la table magasin ne possède pas de id avec une valeur de 8 :
SELECT client.id, nom, magasin_id, code_postal
FROM client
INNER JOIN magasin ON client.magasin_id = magasin.id| id | nom | magasin_id | code_postal |
|---|---|---|---|
| 1 | Beaulieu | 1 | J1K2S8 |
| 2 | Woot | 1 | J1K2S8 |
| 3 | McNicols | 4 | L4X1A7 |
| 5 | Beauregard | 4 | L4X1A7 |
Requêtes imbriquées
Lorsque la requête désirée est particulièrement complexe, il est possible d’imbriquer des requêtes, de faire un SELECT sur le produit d’un autre SELECT. Pour ça, il existe deux méthodes :
Spécifier la première requête dans le FROM de la seconde :
SELECT nom
FROM (
SELECT client.id, nom, magasin_id, code_postal
FROM client
INNER JOIN magasin ON client.magasin_id = magasin.id
) GROUP BY client.id
HAVING magasin_id < 3;Exécuter une première requête et utiliser son retour comme une table :
WITH premiere_requete AS (
SELECT client.id, nom, magasin_id, code_postal
FROM client
INNER JOIN magasin ON client.magasin_id = magasin.id
)
SELECT nom
FROM premiere_requete
GROUP BY id
WHERE magasin_id < 3;Mettre à jour des enregistrements
On peut mettre à jour les enregistrements sélectionnés d’une table avec des critères spécifiques :
UPDATE client -- Table visée
SET nom = 'Martin' -- Champ = nouvelle valeur
WHERE id = 3; -- Filtre pour sélectionner la valeur à mettre à jourNotez que toutes les valeurs de la colonne nom de la table client dont id=3 seront mises à jour pour Martin. Le risque d’erreur est important !!! Testez rigoureusement votre filtre avant d’effectuer la mise à jour.
Supprimer des enregistrements
On peut supprimer des enregistrements sélectionnés d’une table avec des critères spécifiques :
DELETE FROM client
WHERE nom = 'Martin';ATTENTION ! Sans filtres, toutes les valeurs de la table sont supprimées :
DELETE FROM client;CREATE TABLE
Voici un exemple d’instruction SQL pour créer la table auteurs.
CREATE TABLE auteurs (
auteur VARCHAR(50),
statut VARCHAR(40),
institution VARCHAR(200),
ville VARCHAR(40),
pays VARCHAR(40),
PRIMARY KEY (auteur)
);auteursest le nom de la table- Chaque attribut de la table (
auteur,statutetc) dispose d’un type de données (varchar(40),DATE, etc) Type de données SQLite - La dernière ligne correspond aux contraintes de la table telle que la clé primaire.
- Question: Cette clé primaire est composite ou simple?